Neural Network - Why LSTM Works?
In this post, I am trying to understand the reason why LSTM can deal with vanishing and exploding gradient so that it is better than normal RNN in modeling long-term dependencies in sequential data. To start with, we have to comprehend what are vanishing and exploding gradient. Paper [1] is a really good reference to this.
Basically, back propagation is the fundamental method used to train a neural network. In recurrent neural networks (or deep neural networks), due to the reason that the gradient has to propagate back multiple time step, it is running the risk that the gradient will reduce to 0 or explode to a huge number.
1.Vanishing and Exploding Gradient
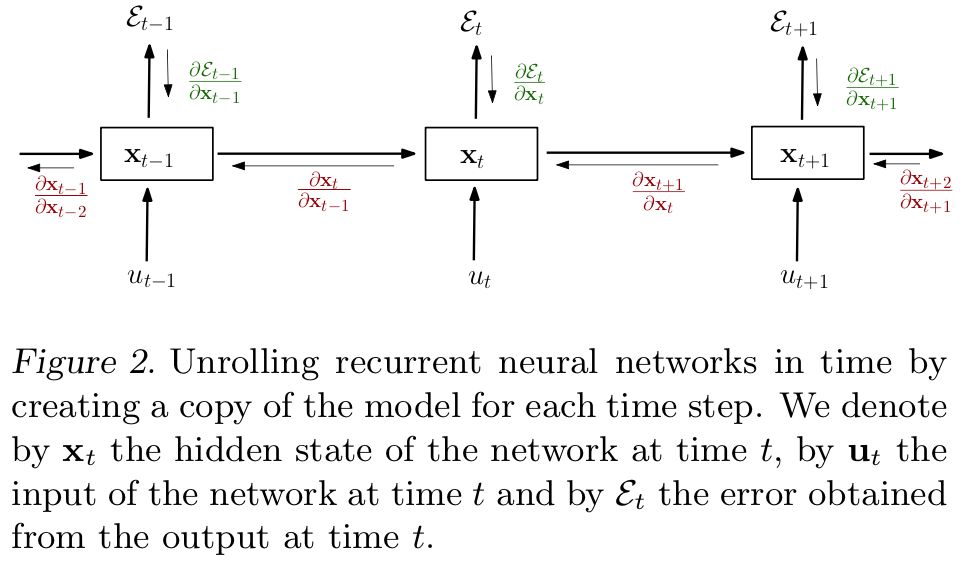
More formally, as shown in Fig.2 (cited from [1]), to perform gradient descent, one has to compute the gradients for the parameters inside the hidden unit. Due to the reason that the hidden unit is shared along all the time steps, the gradients for the parameters inside the hidden unit could be concluded as:
,
where is the error measure (loss) in time
, and
is the group of all error measures from time 1 to
.
While,
is the vector of parameters in the shared hidden unit. Thus, the formula above aggregates the information given by all the error measures in each time step to identify the overall gradient for updating the parameters. Afterward, for each time step, the partial derivative could be further decomposed as:
.
Furthermore, we can find that:
.
Then here comes the question. When is always smaller than a constant
, it has the product of gradients goes to 0 exponentially fast with
:
.
Similarly, if the value of the derivative is always greater than 1 or bigger, it is running the risk of gradient explosion, i.e., the gradient increases exponentially. Note that we are using one-dimensional case here to illustrate the problem. Please refer to [1] for multi-dimensional case.
2.Why LSTM Works?
It is now clear that the key to ease the issue of vanishing and exploding gradient is to carefully manipulate the partial derivative to maintain a reasonable value of the overall gradient
.
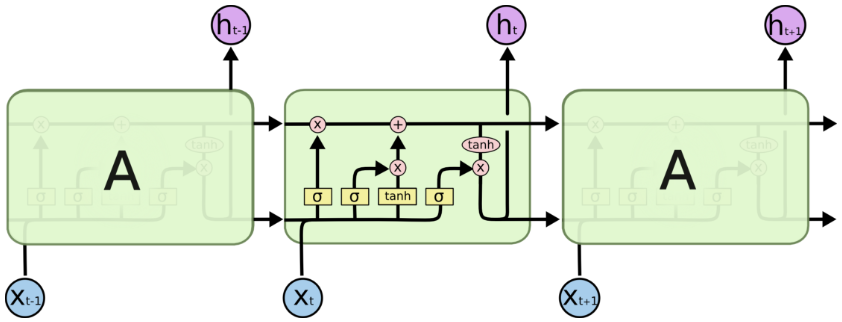
In the figure above (quoted from Colah’s blog), it shows the inner structure of a LSTM unit. The input/output is composed of two parts: a context state and a hidden state (shown below, quoted from Colah’s blog). Sorry for the abuse of notation here. In the figures,
is the input for a LSTM unit, while in the previous section, we use
as the hidden state in a RNN cell.
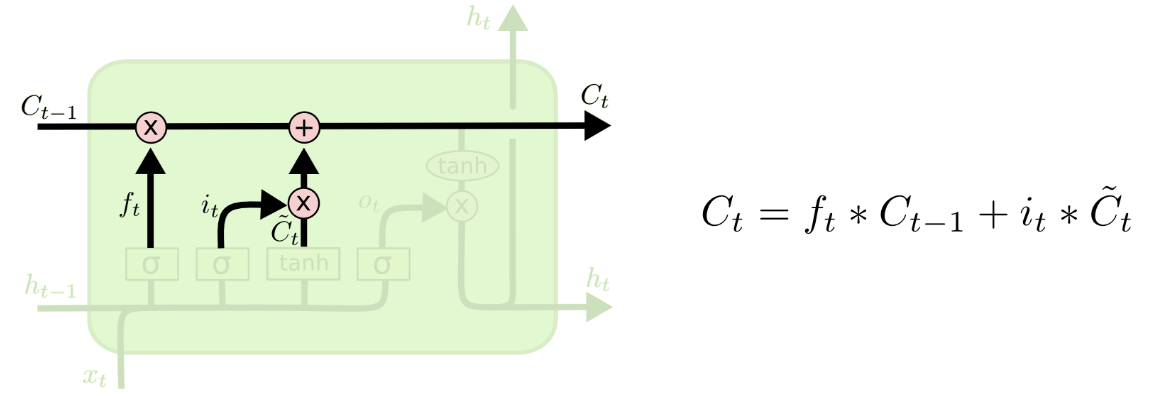
It can be derived from previous section that is still the product of a series of derivatives. We could put it more formally and derive that:
.
This is due to the reason that in each LSTM cell, there are two paths that could affect
.
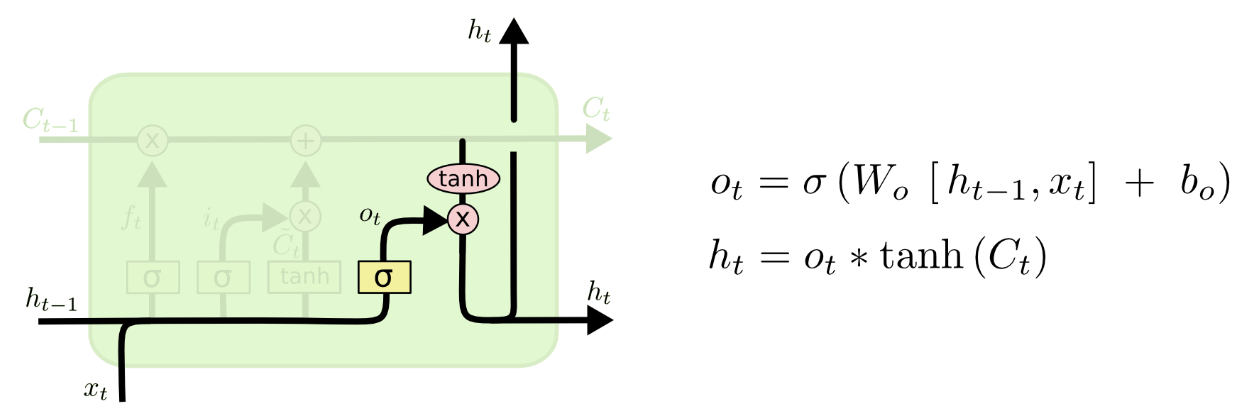
More importantly, it is noticed that, after solving the product, we could find an item:
,
in which the product can be further analysed as (notations could be found in following figure, quoted from Colah’s blog):
It is discussed in thesis [2] (page 14) that the quantity of this product is safe from vanishing and exploding. Therefore, we are optimistic that the overall gradient, i.e., , will not be too small or too big so that same from vanishing and exploding gradient.
Note here again that:
.
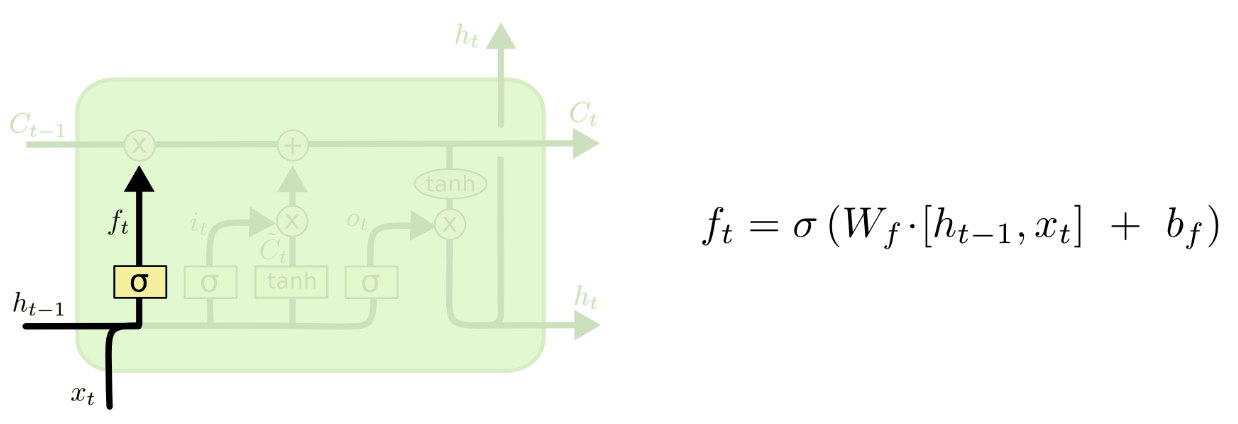
3.Discussion
To be honest, I am not fully convinced by the aforementioned derivation. The key product can certainly approach 0 in specifica cases, although it will not explode. Hence, I am still waiting for better explanation. Practical experiments have shown that LSTM can be trained but it still has limitations in extracting long-term patterns/dependencies of sequential data. Certain research has tried to supersede the utilisation of RNN with other mechanism, e.g., Attention is all you need. Maybe, I mean maybe, RNN is not really necessary?
4.References
[1] Razvan Pascanu, Tomas Mikolov, Yoshua Bengio, On the difficulty of training recurrent neural networks, ICML, vol. 3, no. 28, pp. 1310-1318, 2013.
[2] Justin Simon Bayer, Learning Sequence Representations, Dissertation, Technische Universität München, 2015.